WebRTC Native 代码里面有很多值得学习的宝藏,其中一个就是 WebRTC 的 NetEQ 模块。根据 WebRTC 术语表 对 NetEQ 的解释:
A dynamic jitter buffer and error concealment algorithm used for concealing the negative effects of network jitter and packet loss. Keeps latency as low as possible while maintaining the highest voice quality.
一种动态抖动缓冲区和错误隐藏(丢包补偿)算法,用于去除网络抖动和数据包丢失的负面影响。在保持最高语音质量的同时,保持尽可能低的延迟。
NetEQ 其实就是音视频处理中的 Jitter Buffer 模块,在 WebRTC 的语音引擎中使用。这个模块很重要,会影响播放时的体验,同时也相当复杂。
本文源码参考 WebRTC Native M78 版本。
抖动消除
同码率下:抖动(J) = 平均到达间隔(接近发送间隔) - 单次到达间隔
-
J > 0:正抖动,数据包提前到达,包堆积,接收端溢出
-
J < 0 :负抖动,数据包延迟或丢包
由于网络包的到达有快有慢,导致间隔不一致,这样听感就不顺畅。而抖动消除就是使不统一的延迟变为统一的延迟,所有数据包在网络传输的延迟之和与抖动缓冲区处理后的延迟之和相等。
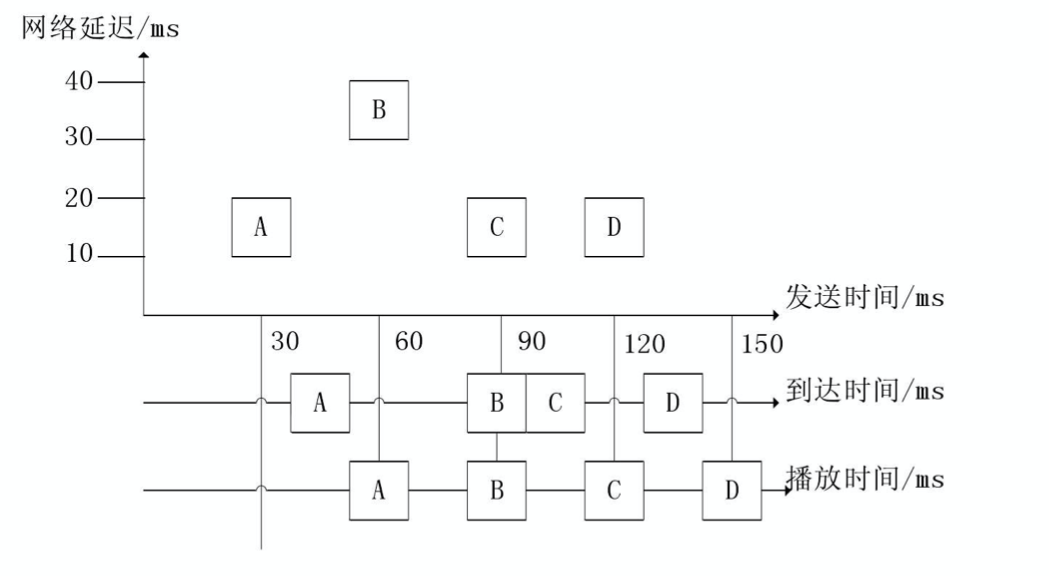
| 时间点 | A | B | C | D |
|---|---|---|---|---|
| 发送 | 30 | 60 | 90 | 120 |
| 到达 | 40 | 90 | 100 | 130 |
| 处理后 | 60 | 90 | 120 | 150 |
通过处理,A、B、C、D 的播放间隔一致,播放端就听感就会感受到延迟,但不会有卡顿。
常见的抖动缓冲控制算法有两种:
-
静态抖动缓冲控制算法:缓冲区大小固定,容易实现,网络抖动大时,丢包率高,抖动小时,延迟大。
-
自适应抖动缓冲控制算法:计算目前最大抖动,调整缓冲区大小,实现复杂,网络抖动大时,丢包率低,抖动小时,延迟小。
好的算法自然是追求低丢包率和低延迟。
丢包补偿
丢包补偿(PLC,Packet Loss Concealment)顾名思义,就是在丢包发生时,做的应对措施。主要分为发送端的接受端的丢包补偿。
发送端
-
主动重传:通过信令,让发送端重新补发。
-
被动通道编码:在组包时做一些特殊处理,丢包时可以作依据。
- 前向差错纠正(FEC,Forward error correction):根据丢包前面的包信息来进行处理。
- 媒体相关:双发,数据包中第二个包一般用较低码率和音质编码的包。
- 媒体无关:每 n 个数据包生成一个(多个)新的校验包,校验包能还原出这 n 个包的信息。
- 交织:对数据包分割重排,减少单次丢包的数据量大小。
- 前向差错纠正(FEC,Forward error correction):根据丢包前面的包信息来进行处理。
接收端
- 插入:用固定的包进行补偿
- 静音包
- 噪音包
- 重复包
- 插值:模式匹配及插值技术生成相似的包,算法不会理解数据包具体内容,而只是从数据特征上进行处理
- 重构:根据编码参数和压缩参数生成包,与插值不同,算法使用更多数据包的信息,效果更好
整体架构
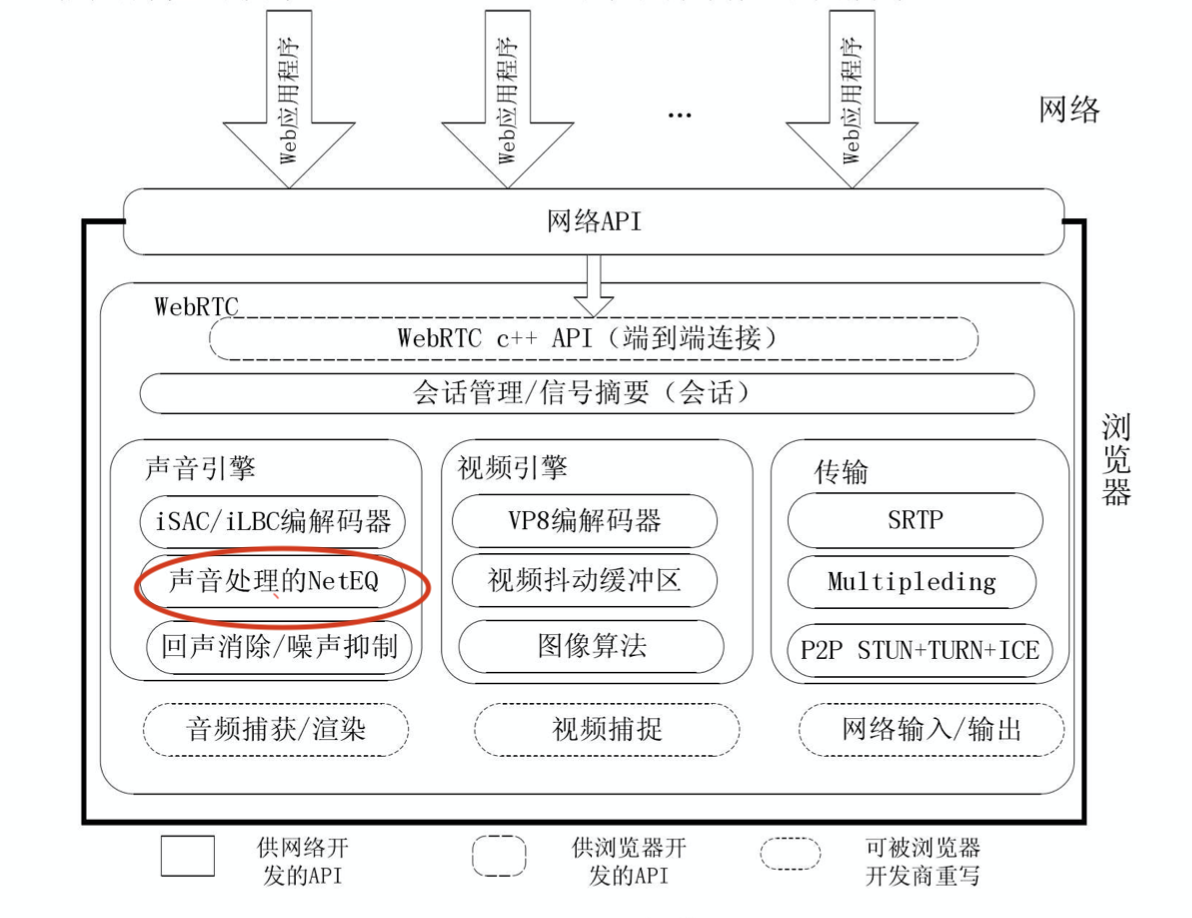
在 WebRTC 源码中,NetEQ 位于语音引擎中。其他的,还有包括编解码器,3A 算法等也很经典和通用的模块。
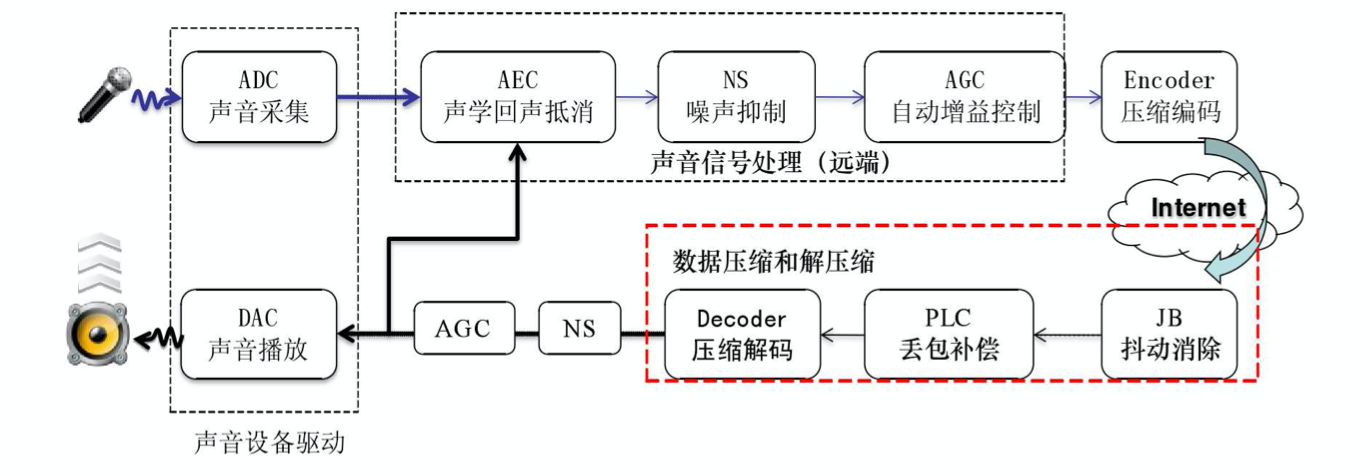
而从声音的处理流程中,NetEQ 在接受端靠前位置,用于处理收到的网络数据包,并传输给下面的具体的音频处理算法。
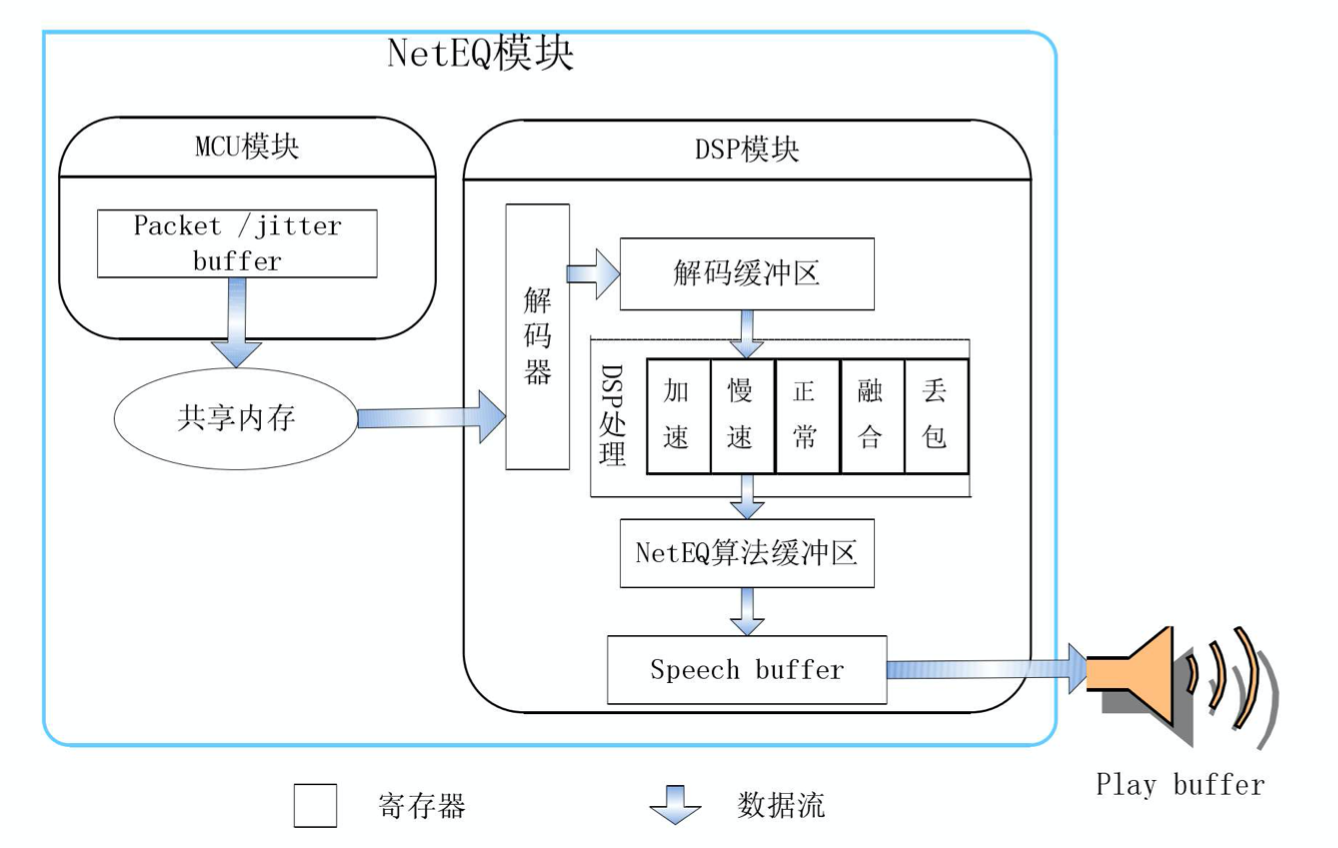
在 NetEQ 模块中,又被大致分为 MCU(Micro Control Unit,微控单元) 模块和 DSP 模块。MCU 主要负责做延时及抖动的计算统计,并生成对应的控制命令。而 DSP 模块负责接收并根据 MCU 的控制命令进行对应的数据包处理,并传输给下一个环节。
MCU 模块
MCU 模块就像指挥部一样。它在接收到数据包后,根据数据包的信息进行统计计算并分析,作出命令决策。主要包括:
网络延时统计算法
这块算法位于 neteq/delay_manager.cc。在接收到包时,会调用
int DelayManager::Update(uint16_t sequence_number,
uint32_t timestamp,
int sample_rate_hz)
将数据包的信息传入,然后更新统计信息。主要流程如下:
- 计算从队列中拉取包的时间到现在的间隔
- 根据包序号,包时间戳,计算延迟
iat_packets间隔的数量- 正常到达:iat_packets=1
- 乱序提前到达:iat_packets=0
- 延迟到达的 n 个间隔:iat_packets=n
- 调用
CalculateTargetLevel更新间隔(根据计算最近一段时间的延迟间隔概率,延迟峰值,进行推算)
int DelayManager::CalculateTargetLevel(int iat_packets, bool reordered)
抖动延迟统计算法
这块算法位于 neteq/buffer_level_filter.cc。在取包时,将调用:
void BufferLevelFilter::Update(size_t buffer_size_samples,
int time_stretched_samples)
将当前抖动缓冲区剩余包的数量和加减速处理过的包量传入,然后更新统计信息。主要流程如下:
- 通过动态的遗忘因子(根据网络延迟值计算),计算平滑延迟
- 计算加减速的影响(time_stretched_samples)
控制命令决策判定
这块算法位于 neteq/decision_logic.cc。在取包时,将调用:
Operations DecisionLogic::GetDecision(const SyncBuffer& sync_buffer,
const Expand& expand,
size_t decoder_frame_length,
const Packet* next_packet,
Modes prev_mode,
bool play_dtmf,
size_t generated_noise_samples,
bool* reset_decoder)
会根据包和前一个包之间的关系,进行判定,给出决策。主要判断条件如下:
- 当前帧正常+前一帧正常:根据网络延时统计值判断,给出正常/加速/减速决策
- 当前帧正常+前一帧丢失:前一帧是补偿产生的,所以要做平滑处理,给出正常/融合决策
- 当前帧丢失+前一帧正常:启用丢包补偿
- 当前帧丢失+前一帧丢失:连续丢包补偿
DSP 处理
变速不变调
代码位于 neteq/time_stretch.cc 中:
TimeStretch::ReturnCodes TimeStretch::Process(const int16_t* input,
size_t input_len,
bool fast_mode,
AudioMultiVector* output,
size_t* length_change_samples)
实现变速不变调,进行语音时长调整,是能进行加减速控制的基础。WebRTC NetEQ 中使用了 WSOLA 算法,但由于此算法过于复杂,以笔者的专业知识无法完全理解,感兴趣见 文章。
正常
代码位于 neteq/normal.cc 中:
int Normal::Process(const int16_t* input,
size_t length,
Modes last_mode,
AudioMultiVector* output)
数据正好符合播放要求,没有什么额外处理,但要考虑上一次包是否为补偿的包,若是则进行平滑处理。
加速
代码位于 neteq/accelerate.cc 中:
Accelerate::ReturnCodes Accelerate::Process(const int16_t* input,
size_t input_length,
bool fast_accelerate,
AudioMultiVector* output,
size_t* length_change_samples)
在抖动延迟过大时,在不丢包的情况下尽量减少抖动延迟。因为这时候数据包累计多,为了尽快消耗数据包,将数据包播放时长缩短。
减速
代码位于 neteq/preemptive_expand.cc 中:
PreemptiveExpand::ReturnCodes PreemptiveExpand::Process(
const int16_t* input,
size_t input_length,
size_t old_data_length,
AudioMultiVector* output,
size_t* length_change_samples)
减速则相反,在网络状况不好时,丢包较多,为了连续性,延长等待网络数据的时间。因为这时候数据包累计少或没有,为了争取等待新的网络数据包的时间,将数据包的播放时长拉长。
融合
代码位于 neteq/expand.cc 中:
Expand::Expand(BackgroundNoise* background_noise,
SyncBuffer* sync_buffer,
RandomVector* random_vector,
StatisticsCalculator* statistics,
int fs,
size_t num_channels)
当上一次播放的帧与当前解码的帧不是连续的情况下,需要来衔接和平滑一下。会让两个数据包一部分播放时间重叠,让过度更自然。
丢包补偿
代码位于 neteq/expand.cc 中:
Expand::Expand(BackgroundNoise* background_noise,
SyncBuffer* sync_buffer,
RandomVector* random_vector,
StatisticsCalculator* statistics,
int fs,
size_t num_channels)
在当前帧丢失时,丢包补偿会参考之前最新的一些样本,通过线性预测重构生成数据,并更新为下次补偿做参考。但由于此算法过于复杂,以笔者的专业知识无法完全理解,感兴趣见 文章.
缓冲区
整个 NetEQ 模块处理过程中,有以下几个缓冲区:
抖动缓冲区
位于 neteq/neteq_impl.h 的 NetEqImpl 类中的 Dependencies 结构体中。
std::unique_ptr<PacketBuffer> packet_buffer
用于存储网络的音频数据包。
解码缓冲区
位于 neteq/neteq_impl.h 的 NetEqImpl 类中。
std::unique_ptr<int16_t[]> decoded_buffer_ RTC_GUARDED_BY(crit_sect_);
用于存储解码后 PCM 数据。
算法缓冲区
位于 neteq/neteq_impl.h 的 NetEqImpl 类中。
std::unique_ptr<AudioMultiVector> algorithm_buffer_ RTC_GUARDED_BY(crit_sect_);
用于存储 DSP 处理后的数据。
语音缓冲区
位于 neteq/neteq_impl.h 的 NetEqImpl 类中。
std::unique_ptr<SyncBuffer> sync_buffer_ RTC_GUARDED_BY(crit_sect_);
其实就是算法缓冲区的数据复制,增加了已播放位置分割标识。
进包处理
进包处理流程代码位于 neteq/neteq_impl.cc 中的 InsertPacket 方法中,此方法调用了真正处理的内部方法:
int NetEqImpl::InsertPacketInternal(const RTPHeader& rtp_header,
rtc::ArrayView<const uint8_t> payload,
uint32_t receive_timestamp)
总体流程如下:
-
将数据放入局部变量 PacketList 中
-
处理 RTP 包逻辑
- 转换内外部时间戳
- NACK(否定应答) 处理
- 判断冗余大包(RED)并解为小包
- 检查包类型
- 判断并处理 DTMF(双音多频) 包
- 带宽估算
-
分析包
- 去除噪音包
- 解包头获取包的信息
- 计算除纠错包和冗余包以外的正常语音包数量
-
将语音包插入 PacketBuffer(抖动缓冲区)
出包处理
出包处理流程代码位于 neteq/neteq_impl.cc 中的 GetAudio 方法中,此方法调用了真正处理的内部方法:
int NetEqImpl::GetAudioInternal(AudioFrame* audio_frame,
bool* muted,
absl::optional<Operations> action_override)
总体流程如下:
- 检查静音状态,直接返回静音包
- 根据当前帧和前一帧的接收情况获取控制命令决策
- 若非丢包补偿,进行解码,放入解码缓冲区
- 进行静音检测(Vad)
- 根据命令决策,将解码缓冲区进行处理,放到算法缓冲区(AudioMultiVector)
- 将算法缓冲区的数据拷贝到语音缓冲区(SyncBuffer)
- 处理并取出 10ms 的语音数据输出
拓展 - 如何设计 Jitter Buffer
根据 WebRTC 的 NetEQ 模块,笔者总结了以下设计 Jitter Buffer 需要注意的几点:
- 接口 - putPacket/getPacket
- 包处理 - 类型判断/分割为播放帧
- 乱序接收处理 - Sequence/Timestamp
- 抖动/延时统计值计算
- 取帧位置/容量变化 - 根据包接收的状况
- 音频参数切换 - Reset
- 丢包补偿 - 参考历史包进行重构
最后
WebRTC NetEQ 模块大概介绍完毕了。正是因为 Google 将其开源,才能一窥究竟,而大部分自研的语音引擎,或多或少都参考过 NetEQ 里的策略。不得不说,WebRTC 真是音视频领域的值得学习的好源码。